Moz Developer Blog
Moz engineers writing about the work we do and the tech we care about.
Why Didn't Moz Crawl My Site?
Posted by David Barts on November 17, 2014
When a campaign results in only a few pages (or none at all) being crawled, customers frequently ask the above question. Typically, it’s a newly created campaign that prompts such a question, but sometimes an existing one suddenly has far fewer pages being crawled. If this has happened to you, this post is for you: There are a number of good reasons why this happens, and they are all fixable! To help you figure out why Moz isn’t crawling all of your pages, and how to fix it, read on. I’ve broken the possible reasons down into several broad categories, discussed in the sections that follow.
Reason #1: The Moz Custom Crawler is not a search engine
Both search engine crawlers and our crawler crawl web sites, but their goals are slightly different. A search engine crawler’s goal is to do whatever it takes to try and crawl a web site. Our crawler’s goal is to gather information that will help you to make a web site that ranks as highly as possible by the search engines.
Why this is good
What this means is that our crawler is deliberately a bit fussier than a search engine’s crawler. When it gets a strange or bad response, it gives up a little sooner and surfaces a page or site issue about the problem. That’s because we care that your site doesn’t only appear in the search engines, but that it is ranked highly (ideally, in the #1 spot). That’s at the heart of SEO. If you’re doing the absolute minimum for your web site to appear, it could suddenly disappear from search engine rankings when Google or Bing updates their crawlers to be slightly less forgiving. We’re helping you avoid that by pointing out these crawl issues before they become a problem.How to fix
Review your Moz Analytics Crawl diagnostics periodically to see if there are any issues cropping up. If there are, set aside some time to fix them before they start impacting your rankings.Reason #2: A crawl is a snapshot in time
If your site is all or mostly un-crawlable (defined as yielding fewer than 10 crawled pages), our crawler will try again a few times before it gives up and returns minimal results. If these retries all fail, your latest batch of crawl results will reflect only that failed crawl, and not any previous successful crawls. That’s different behavior from most search engines that retry more times and then present results based on the most recent successful crawls (at least, until the site persistently fails and the engine proclaims it dead).Why this is good
Again, our job is to be fussier than a search engine. A web site that is unreliably crawlable is a site that will tend to send customers to your competitors. Also, it's our job to show you the most recent data we could gather about your site, which means data gathered in the most recent crawl of it. This distinction is both so you can see the results of any positive SEO efforts you’ve been working on, and so you are quickly alerted to any problems that crop up (hopefully before the search engines find them).How to fix
If you’re suddenly getting low crawl results, it can be helpful to know the exact time a page was crawled when it returned an error to our server. That information isn’t currently surfaced in Moz Analytics, but the crawlers do gather it, so if you’re completely stumped as to why our crawler got an error, our Help Team should be able to get that information to you. You can then check your server logs for that time and date to see if something changed.Reason #3: A lot can hinder crawling behind the scenes
Another way to say that is, "Crawling is complicated." To fetch a single page (without any redirects), our crawler takes the following steps, and at each step, it’s possible one problem or another blocks the crawler: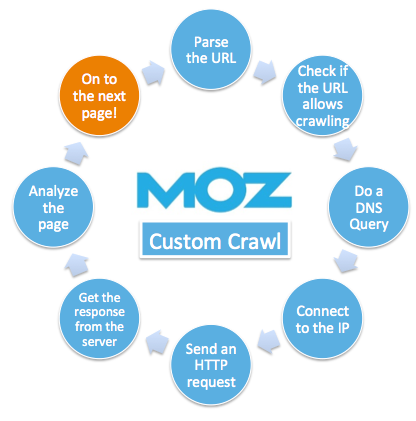
- Parse the URL. This happens entirely on our end. If it fails, the crawler throws away the offending URL without even attempting to crawl it. This might cause fewer pages to be crawled than you were expecting, if your site contains a lot of garbled URLs.
- Check if the URL allows crawling. If it lies outside the specified domain or subdomain of the crawl, or if the URL bans our crawler in its robots.txt file, then our crawler won’t crawl the page. Game over for that URL and any other pages it links to.
- Do a DNS query. So, we’ve parsed the URL and crawling is allowed. Now we take the host name part of the URL and issue a DNS query to resolve that name into a numeric IP address. If the name server for your domain is down or unreachable, again: game over. The page fetch will fail with a 901 error.
- Connect to the IP. If that succeeds, we now have an IP address. The crawler attempts to open a TCP stream connection to an appropriate port (typically either 80 for http or 443 for https) on that host. If the connection attempt fails, then the page fetch will fail with the appropriate error code. The connection can fail due to network errors preventing us from contacting the server, the server failing to respond, the server responding but refusing our connection, or the server closing the connection as soon as we opened it. One reason for a failure of this type would be a site configured to block all requests coming from Amazon AWS hosts (our crawlers are currently hosted by Amazon AWS).
- Send an HTTP request. When we have an open connection to your server, we use it to send an HTTP request for the page of interest. If that request fails (maybe a network error causes the connection to be lost, or maybe the server closes the connection early), then again the page fetch fails.
- Get the response from the server. When the request succeeds, we read the response from the server. If the server doesn’t complete the response within a reasonable time, the connection is unexpectedly lost mid-response, or the response is so badly garbled that we can't make sense of it, then the page fetch will fail.
- Analyze the page. Following fetching, we then parse the page as HTTP and analyze it. If the Content-Type response header indicates non-HTTP content, or if the content is garbled enough that our reasonably-lenient HTTP parser cannot make sense of it, then no links are found and those links can’t be enqueued for crawling from that page.
- User-agent discrimination bans Rogerbot: Some sites practice what is known as "user agent discrimination." If an HTTP request comes in and its User-Agent header line does not indicate a well-known browser, the site is coded to return minimal or no content for the request. Since Rogerbot is TAGFEE and identifies as himself instead of attempting to mimic what a browser would send, user-agent discrimination tends to make sites un-crawlable for him. User-agent discrimination also is not just undesirable for our crawlers… it’s also an undesirable thing to do from an SEO perspective.
- Cookies are enforced: Some sites try to enforce the use of cookies by sending a cookie-containing redirect response to the same page. Our crawler currently does not support cookies, so it sees such redirects as nothing more than circular redirect attempts (which it refuses to chase).
- JavaScript is required: Some sites make JavaScript mandatory and have all their meaningful content inside of scripts. Our crawler only understands HTTP, so such pages look mostly empty to it.