Moz Q&A is closed.
After more than 13 years, and tens of thousands of questions, Moz Q&A closed on 12th December 2024. Whilst we’re not completely removing the content - many posts will still be possible to view - we have locked both new posts and new replies. More details here.
A question about RSS feeds and nofollow's
-
With the nofollow tag used very widely on the internet these days I was just wondering about how an RSS feed might help me find a way around it. Basically my question is this : I post a comment on a blog, it's approved and my comment together with my link(nofollow tag applied) is there. Now when the blogs RSS feed updates, does this nofollow tag get applied to the feed? As far as I can tell it does not - but I'm not too clue'd up on how the feed is generated.
Anyone want to help me understand how it works and if what I'm suggesting would be 'a way around the nofollow tag' ?
Thanks
")
-
Thanks Alan - I'm not looking for brute force link building was just curious about the concept
-
@Alan +1
-
Regardless of whether they're updated or not, RSS feeds are generating duplicate content and not the original source, so the value is going to be either none, or more likely, less than comments on an original source. And if you're actually here asking this question, I'd suggest that unless you perform a specific test, in a specific situation across a specific market niche, you're not always going to get the same results.
And unless you're looking for brute force link building, it seems like a poor time expense to pursue these given the dupe-content factor. And if you are looking for brute force link building, don't rely on this method being sustainable.
-
What about dynamically created blogs and databases - surely comments are also stored in the database and then retrieved when the visitor requests the 'page' ? That would keep updating the feed atleast daily when the cron job is run?
And the commentRSS feed is a dofollow? That can be indexed by the search engine and still sits on the domain? Cos that then sounds to me like a dofollow link coming effectively from the domain of the blog?!
-
If you are talking about a commentRSS feed yes, it´s updated when you write a new comment, but the RSS show nofollow tag too. If you are talking about a normal blog RSSfeed, the new comments don´t update the RSS.
-
Surely that can'y be the case - since one of the uses for an RSS feed is to track when someone has replied to your comment/made another comment?
-
Yes, and the comments don´t update the blog RSS feed.
Browse Questions
Explore more categories
-
Moz Tools
Chat with the community about the Moz tools.
-
SEO Tactics
Discuss the SEO process with fellow marketers
-
Community
Discuss industry events, jobs, and news!
-
Digital Marketing
Chat about tactics outside of SEO
-
Research & Trends
Dive into research and trends in the search industry.
-
Support
Connect on product support and feature requests.
Related Questions
-

Duplicate content issue with ?utm_source=rss&utm_medium=rss&utm_campaign=
Hello,
Technical SEO | | Dinsh007
Recently, I was checking how my site content is getting indexed in Google and from today I noticed 2 links indexed on google for the same article: This is the proper link - https://techplusgame.com/hideo-kojima-not-interested-in-new-silent-hills-revival-insider-claims/ But why this URL was indexed, I don't know - https://techplusgame.com/hideo-kojima-not-interested-in-new-silent-hills-revival-insider-claims/?utm_source=rss&utm_medium=rss&utm_campaign=hideo-kojima-not-interested-in-new-silent-hills-revival-insider-claims Could you please tell me how to solve this issue? Thank you1 -

Google has deindexed a page it thinks is set to 'noindex', but is in fact still set to 'index'
A page on our WordPress powered website has had an error message thrown up in GSC to say it is included in the sitemap but set to 'noindex'. The page has also been removed from Google's search results. Page is https://www.onlinemortgageadvisor.co.uk/bad-credit-mortgages/how-to-get-a-mortgage-with-bad-credit/ Looking at the page code, plus using Screaming Frog and Ahrefs crawlers, the page is very clearly still set to 'index'. The SEO plugin we use has not been changed to 'noindex' the page. I have asked for it to be reindexed via GSC but I'm concerned why Google thinks this page was asked to be noindexed. Can anyone help with this one? Has anyone seen this before, been hit with this recently, got any advice...?
Technical SEO | | d.bird0 -

If I'm using a compressed sitemap (sitemap.xml.gz) that's the URL that gets submitted to webmaster tools, correct?
I just want to verify that if a compressed sitemap file is being used, then the URL that gets submitted to Google, Bing, etc and the URL that's used in the robots.txt indicates that it's a compressed file. For example, "sitemap.xml.gz" -- thanks!
Technical SEO | | jgresalfi0 -

Spam URL'S in search results
We built a new website for a client. When I do 'site:clientswebsite.com' in Google it shows some of the real, recently submitted pages. But it also shows many pages of spam url results, like this 'clientswebsite.com/gockumamaso/22753.htm' - all of which then go to the sites 404 page. They have page titles and meta descriptions in Chinese or Japanese too. Some of the urls are of real pages, and link to the correct page, despite having the same Chinese page titles and descriptions in the SERPS. When I went to remove all the spammy urls in Search Console (it only allowed me to temporarily hide them), a whole load of new ones popped up in the SERPS after a day or two. The site files itself are all fine, with no errors in the server logs. All the usual stuff...robots.txt, sitemap etc seems ok and the proper pages have all been requested for indexing and are slowly appearing. The spammy ones continue though. What is going on and how can I fix it?
Technical SEO | | Digital-Murph0 -

301 Re-directing 'empty' domains
Hello, My client had purchased a few domains and 301 re-directed them, pointing to our main website. As far as I am aware the 'empty domains' are brand related but no content has ever been displayed on them, and I doubt they have much authority. The issue here is that we took a dive in ranking for our main keyword, I had a look on ahrefs and found the below: | www.empty-domain/our-keyword | 30 | 19 | 1 | fb 0
Technical SEO | | SO_UK
G+ 0
in 4 | REDIRECT 301 TO www.main-domain/our-keyword | 8 Feb '175 d | The ranking dip happened at the same time as the re-direct was re-discovered / re-crawled. Could the 'empty' URL in question been causing us any issues? I understand that this is terrible practice for 301 redirects, I was hoping someone in the community could shed light on any possible solution for this.0 -

Should I noindex my blog's tag, category, and author pages
Hi there, Is it a good idea to no index tag, category, and author pages on blogs? The tag pages sometimes have duplicate content. And the category and author pages aren't really optimized for any search term. Just curious what others think. Thanks!
Technical SEO | | Rignite0 -

Does Title Tag location in a page's source code matter?
Currently our meta description is on line 8 for our page - http://www.paintball-online.com/Paintball-Guns-And-Markers-0Y.aspx
Technical SEO | | Istoresinc The title tag, however sits below a bunch of code on line 237
The title tag, however sits below a bunch of code on line 237
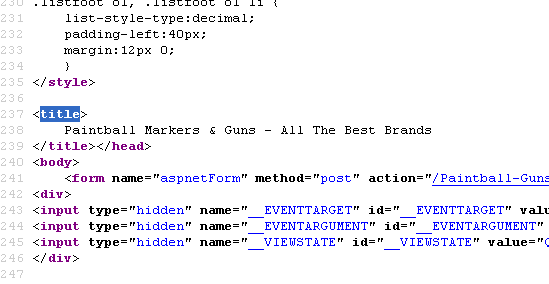 Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0
Does the location of the title tag, meta tags, and any structured data have any influence with respect to SEO and search engines? Put another way, could we benefit from moving the title tag up to the top?
I "surfed 'n surfed" and could not find any articles about this.
I would really appreciate any help on this as our site got decimated organically last May and we are looking for any help with SEO.
NIck
0 -

Should we use Google's crawl delay setting?
We’ve been noticing a huge uptick in Google’s spidering lately, and along with it a notable worsening of render times. Yesterday, for example, Google spidered our site at a rate of 30:1 (google spider vs. organic traffic.) So in other words, for every organic page request, Google hits the site 30 times. Our render times have lengthened to an avg. of 2 seconds (and up to 2.5 seconds). Before this renewed interest Google has taken in us we were seeing closer to one second average render times, and often half of that. A year ago, the ratio of Spider to Organic was between 6:1 and 10:1. Is requesting a crawl-delay from Googlebot a viable option? Our goal would be only to reduce Googlebot traffic, and hopefully improve render times and organic traffic. Thanks, Trisha
Technical SEO | | lzhao0